SLO Documentation & Error Budget Policy
Make Sure you have read previous post before reading this one
In this post we will discuss on :
- why documenting SLOs is important.
- why documenting the consequences of missing SLOs is important.
- Error budget policy
The product is build with the collaboration from multiple teams, there would be more than one stakeholder for the product. Everyone in team working on the service like product managers, developers, SREs and executives, need to know what are the SLO’s and what it intends to happen when SLO’s breach the thresholds. It’s never efficient or good have people discussing the course of action during an outage, so it’s very important to document your SLO’s.Simply programming and configuring the monitoring system isn’t good enough, need to mention on what logical basis SLO implementation is done, it will help everyone who works on your service to understand and reason about the impact of an SLO miss. It’s also recommended that the documentation also includes some justification for:
- why the threshold is set at that value,
- why the SLIs are appropriate for measuring the SLO
- Any monitoring data deliberately included or excluded from the SLIs.
After any outage, and post doing postmortem or root-cause analysis if it results in changing the thresholds, it would be good to attach it to the document.It always better to keep your configuration of the SLO’s in a version control system, so we could roll-back or see the historical change, if we need to re-analyze.
Once you have documented and implemented your SLO’s the next important task is to create a dashboard, in which live metrics (your SLI’s) are published. It could be used by the support technician in case of any issues. It doesn’t matter if you are using Grafana, Kibana(to which your pushing metrics), Stackdriver, it’s that you should have a dashboard.
Sample:
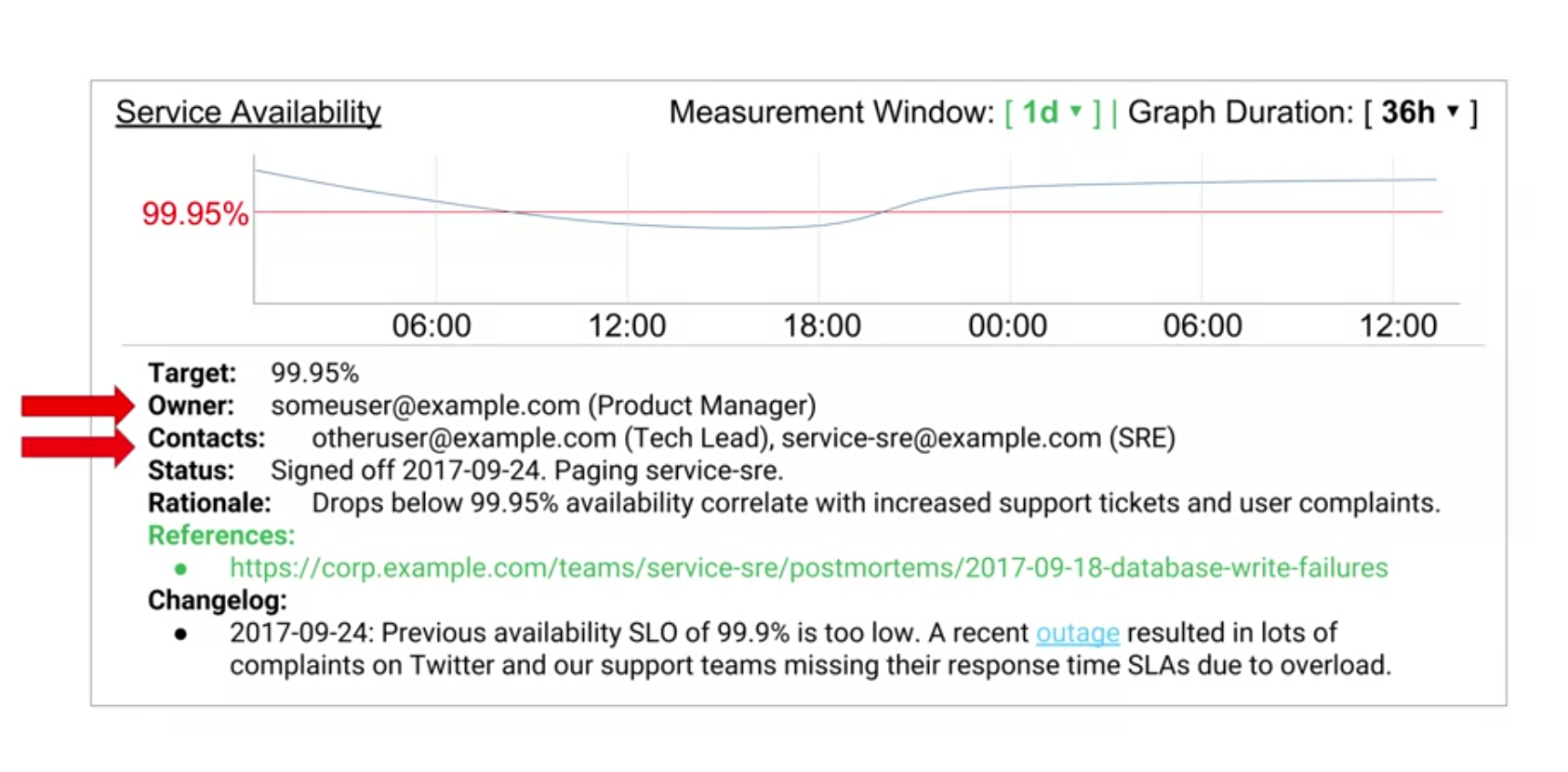
Error Budget Policy :
Error budgets are one of the main tools SREs have to prioritize reliability.As important as error budgets are,it’s equally important to have an error budget policy for the team. It should be on the overall best interests of the business that there’s some mechanism to enforce, that the engineering time is invested in reliability work when an SLO’s has been missed, and you have exceeded your error budget, and error budget policy is the one which could used as reference to make the switch. An error budget policy describes how your team should decide to trade off reliability work against other feature work when this SLO indicates a service is not reliable enough. The purpose of such a policy is to guide your team into meaningful and appropriate action when the reliability of your service is threatened. If your business implements and follows an error budget policy, it will be able to respond more quickly and effectively to critical reliability issues, rather starting the blame game and ultimately resulting in unhappy customers.
An effective error budget policy :
- Result in switching engineering efforts to improve reliability if the error budget is exhausted.
- Should be clear about when it takes effect
- policy should also include consequences if this reliability work is just not happening or getting prioritized
- Should be signed by all parties involved (dev and sre teams)
- Document the escalation process