Developing SLO and SLI
Make Sure you have read previous post before reading this one
The process of developing SLIs and SLOs for a user trace can be broken into following steps.
- what types of SLI you want to measure for the user journey, and set specifications for these SLIs
- Describe which events have to be measured, any validity restrictions to the scope of the SLI. Also define what makes an event good and which all are valid events.
- Weigh the pros and cons of the various measurement strategies, and figure out where and how the SLI will be measured
- SLI implementations need to be detailed enough that someone could build or configure monitoring infrastructure to gather the data without needing to consult
- Document on the failure modes that your SLIs won’t capture, hopefully there won’t be many.
- choose your measurement window and set some SLO targets, either based on historical data or can estimate based on the business requirement
Example :
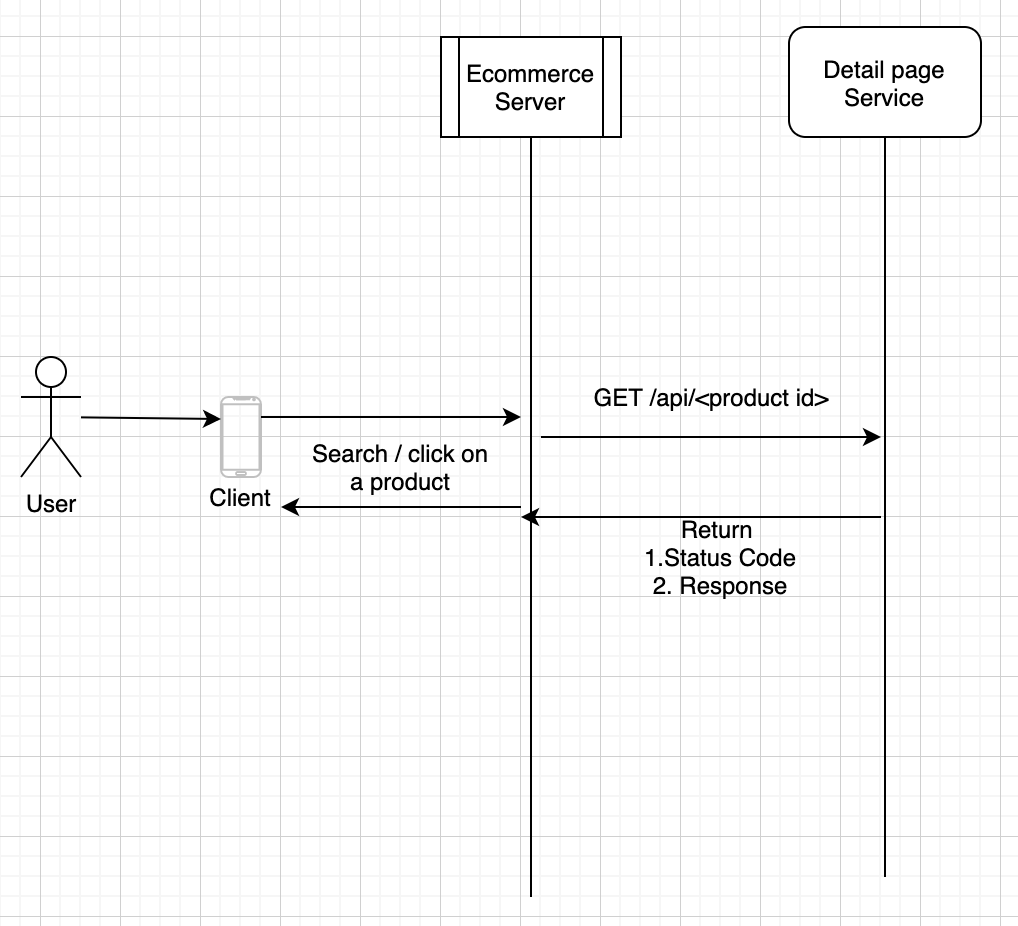
The above is an example of user journey of viewing the product details in the app. I have considered the above route and
keeping it simple. In actual scenario the response would be obtained via connecting to multiple micro services. What do you
think the users expectation would be on selecting the product seen in the search page? what would make them happy and unhappy?.
The client’s browser/app will make a https request to the server which the load balancer will route to one of the
web servers to serve the response. The JS and CSS assets will be pulled via the CDN by the client, and the page is compiled
at client side and full product detail page is shown to the user. From a user perspective, the user would be happy only
if the page loads as quickly as possible, displaying all the details. This example is more over like a Request/Response interaction,
so we want to measure both the availability and latency metrics are measured. This raises a question: what does successful
loading of page or when we say quickly loaded means?. When we define the SLI it should be clear, what, where and how are
we measuring the SLI’s. When you are pre-paring a SLI document, it should be pretty clear, anyone with that document should
just be able to start without any concerns or queries. Coming back to this scenario so we have decided availability and
latency are the metrics we need to measure, for measuring the availability, let’s say we need to check if the page/product
page was successfully served or not for this we could depend on the status code response, which would get recorded in the
load balancer as it returns the response. To be more precise, we could tell let’s say, consider all requests with request
path /api/product
There could be lot of gaps, in the settings we have done we always need to walk through the user journey and consider if the chosen measurement strategy will observe the SLI metrics, if the infrastructure fails. That is let’s say if the load balancer is down, our SLI metrics won’t be populating and we wouldn’t be knowing what’s happening. This clearly calls out that the postmortem or Root cause analysis is always important, as it would not only able to help you find the issue but also help in placing the right metrics and methods to monitor. One solution I think is to create a one-box stage in my pipeline to which ill be supplying synthetic traffic and would be monitoring the response, and will also we watching on missing or empty data/monitoring points. Capturing all the falls at first go for complex systems are always unrealistic, it would always be an incremental enhancement.